> For the complete documentation index, see [llms.txt](https://maheshwarappa-a.gitbook.io/data-science-interview/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://maheshwarappa-a.gitbook.io/data-science-interview/machine-learning/basic-questions.md).
# Basic questions
## 1.**What is a confusion matrix?**
The confusion matrix is a 2X2 table that contains 4 outputs provided by the **binary classifier**. Various measures, such as error-rate, accuracy, specificity, sensitivity, precision and recall are derived from it. *Confusion Matrix*
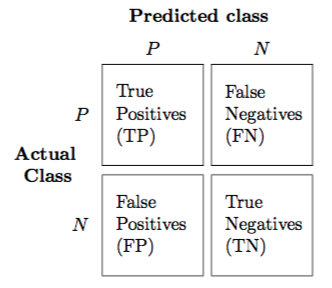
**Basic measures derived from the confusion matrix**
1. Error Rate = $$(FP+FN)/(P+N)$$
2. Accuracy = $$(TP+TN)/(P+N)$$
3. Sensitivity(Recall or True positive rate) = $$TP/P$$
4. Specificity(True negative rate) = $$TN/N$$
5. Precision(Positive predicted value) = $$TP/(TP+FP)$$
6. F-Score(Harmonic mean of precision and recall) =
$$
\frac{(1+b(PREC.REC)}{(b²PREC+REC)}
$$
1. where b is commonly 0.5, 1, 2.
## **2.How to combat Overfitting and Underfitting?**
To combat overfitting and underfitting, you can resample the data to estimate the model accuracy (k-fold cross-validation) and by having a validation dataset to evaluate the model.
## **3. What Are Confounding Variables?**
In statistics, a confounder is a variable that influences both the dependent variable and the independent variable.
For example, if you are researching whether a lack of exercise leads to weight gain,
**lack of exercise = independent variable**
**weight gain = dependent variable.**
A confounding variable here would be any other variable that affects both of these variables, such as the **age of the subject**.
## **4. ROC curve works?**
The **ROC** curve is a graphical representation of the contrast between true positive rates and false-positive rates at various thresholds. It is often used as a proxy for the trade-off between the sensitivity(true positive rate) and false-positive rate
### ROC curve
An **ROC curve** (**receiver operating characteristic curve**) is a graph showing the performance of a classification model at all classification thresholds. This curve plots two parameters:
* True Positive Rate
* False Positive Rate
#### **True Positive Rate** (**TPR**)
is a synonym for recall and is therefore defined as follows:
$$
TPR = \frac{TP}{TP+FN}
$$
**False Positive Rate** (**FPR**) =
$$
\frac{FP}{FP + TN}
$$
An ROC curve plots TPR vs. FPR at different classification thresholds. Lowering the classification threshold classifies more items as positive, thus increasing both False Positives and True Positives. The following figure shows a typical ROC curve.

To compute the points in an ROC curve, we could evaluate a logistic regression model many times with different classification thresholds, but this would be inefficient. Fortunately, there's an efficient, sorting-based algorithm that can provide this information for us, called AUC.
### AUC: Area Under the ROC Curve
**AUC** stands for "Area under the ROC Curve." That is, AUC measures the entire two-dimensional area underneath the entire ROC curve (think integral calculus) from (0,0) to (1,1).

**Figure 5. AUC (Area under the ROC Curve).**
AUC provides an aggregate measure of performance across all possible classification thresholds. One way of interpreting AUC is as the probability that the model ranks a random positive example more highly than a random negative example. For example, given the following examples, which are arranged from left to right in ascending order of logistic regression predictions:

**Figure 6. Predictions ranked in ascending order of logistic regression score.**
AUC represents the probability that a random positive (green) example is positioned to the right of a random negative (red) example.
AUC ranges in value from 0 to 1. A model whose predictions are 100% wrong has an AUC of 0.0; one whose predictions are 100% correct has an AUC of 1.0.
AUC is desirable for the following two reasons:
* AUC is **scale-invariant**. It measures how well predictions are ranked, rather than their absolute values.
* AUC is **classification-threshold-invariant**. It measures the quality of the model's predictions irrespective of what classification threshold is chosen.
However, both these reasons come with caveats, which may limit the usefulness of AUC in certain use cases:
* **Scale invariance is not always desirable.** For example, sometimes we really do need well calibrated probability outputs, and AUC won’t tell us about that.
* **Classification-threshold invariance is not always desirable.** In cases where there are wide disparities in the cost of false negatives vs. false positives, it may be critical to minimize one type of classification error. For example, when doing email spam detection, you likely want to prioritize minimizing false positives (even if that results in a significant increase of false negatives). AUC isn't a useful metric for this type of optimization.
## **5. What is TF/IDF vectorization?**
TF–IDF is short for term frequency-inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus. It is often used as a weighting factor in information retrieval and text mining.
The TF–IDF value increases proportionally to the number of times a word appears in the document but is offset by the frequency of the word in the corpus, which helps to adjust for the fact that some words appear more frequently in general.