Gradient Boosting Machine (GBM)
Gradient Boosting or GBM is another ensemble machine learning algorithm that works for both regression and classification problems. GBM uses the boosting technique, combining a number of weak learners to form a strong learner. Regression trees used as a base learner, each subsequent tree in series is built on the errors calculated by the previous tree.
We will use a simple example to understand the GBM algorithm. We have to predict the age of a group of people using the below data:
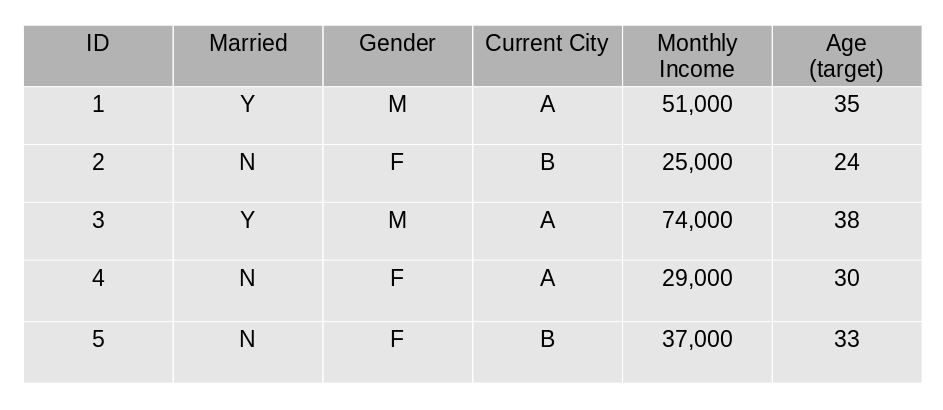
The mean age is assumed to be the predicted value for all observations in the dataset.
The errors are calculated using this mean prediction and actual values of age.
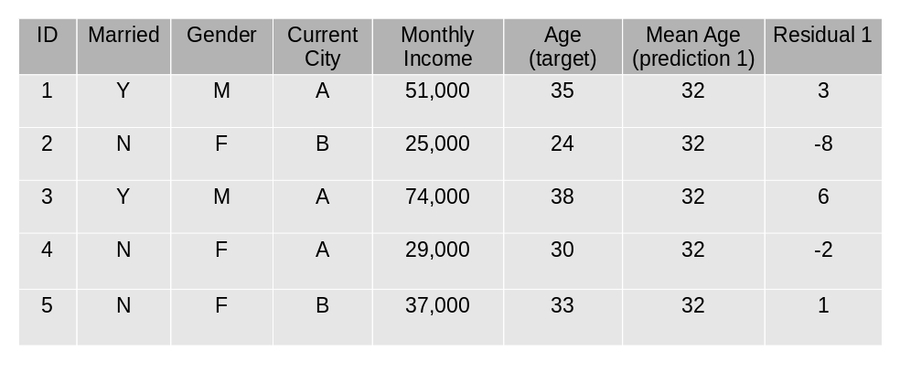
A tree model is created using the errors calculated above as target variable. Our objective is to find the best split to minimize the error.
The predictions by this model are combined with the predictions 1.
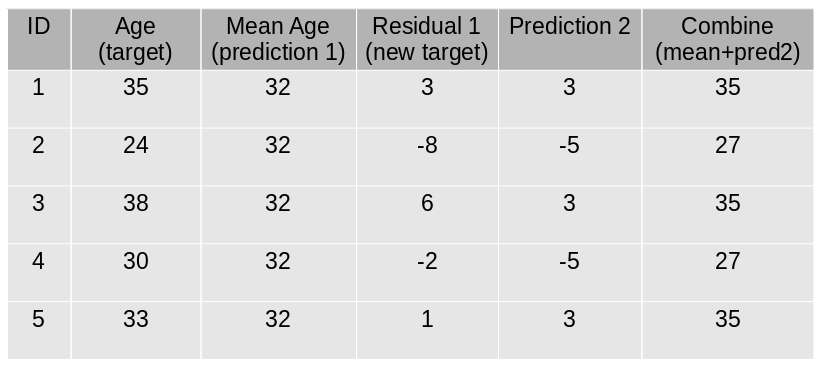
This value calculated above is the new prediction.
New errors are calculated using this predicted value and actual value.

Steps 2 to 6 are repeated till the maximum number of iterations is reached (or error function does not change).
Code:
Sample code for regression problem:
Parameters
min_samples_split
Defines the minimum number of samples (or observations) which are required in a node to be considered for splitting.
Used to control over-fitting. Higher values prevent a model from learning relations which might be highly specific to the particular sample selected for a tree.
min_samples_leaf
Defines the minimum samples required in a terminal or leaf node.
Generally, lower values should be chosen for imbalanced class problems because the regions in which the minority class will be in the majority will be very small.
min_weight_fraction_leaf
Similar to min_samples_leaf but defined as a fraction of the total number of observations instead of an integer.
max_depth
The maximum depth of a tree.
Used to control over-fitting as higher depth will allow the model to learn relations very specific to a particular sample.
Should be tuned using CV.
max_leaf_nodes
The maximum number of terminal nodes or leaves in a tree.
Can be defined in place of max_depth. Since binary trees are created, a depth of ‘n’ would produce a maximum of 2^n leaves.
If this is defined, GBM will ignore max_depth.
max_features
The number of features to consider while searching for the best split. These will be randomly selected.
As a thumb-rule, the square root of the total number of features works great but we should check up to 30-40% of the total number of features.
Higher values can lead to over-fitting but it generally depends on a case to case scenario.
Last updated