Ensembling, Bagging, Boosting, Tree-based Models
1.Ensemble
In statistics and machine learning, ensemble methods use multiple learning algorithms to obtain better predictive performance than could be obtained from any of the constituent learning algorithms alone
Ensemble methods is a machine learning technique that combines several base models in order to produce one optimal predictive model
1.1.Why do we need to know about Ensemble Learning?
Ensemble learning is one of the most effective ways to build an efficient machine learning model. You can build an ensemble machine learning model using simple models and yet get great scores which are at par with the resource-hungry models like neural networks.
1.2.What are the different types of Ensemble Learning techniques?
There are simple and advanced ensemble learning techniques.
Simple:
Max Voting
Averaging
Weighted Averaging
Advanced
Stacking
Blending
Bagging
Boosting
2.Bootstrapping
Bootstrapping is a sampling technique in which we create subsets of observations from the original dataset, with replacement. The size of the subsets is the same as the size of the original set.
The Bootstrap -
widely applicable and extremely powerful statistical tool bootstrap that can be used to quantify the uncertainty associated with a given estimator or statistical learning method
3. Bagging (or Bootstrap Aggregating)
Technique uses these subsets (bags) to get a fair idea of the distribution (complete set). The size of subsets created for bagging may be less than the original set.
Bagging stands for bootstrap aggregation. One way to reduce the variance of an estimate is to average together multiple estimates.
Bootstrap Aggregation (or Bagging for short), is a simple and very powerful ensemble method. Bagging is the application of the Bootstrap procedure to a high-variance machine learning algorithm, typically decision trees.
Suppose there are N observations and M features. A sample from observation is selected randomly with replacement(Bootstrapping).
A subset of features are selected to create a model with sample of observations and subset of features.
Feature from the subset is selected which gives the best split on the training data.(Visit my blog on Decision Tree to know more of best split)
This is repeated to create many models and every model is trained in parallel
Prediction is given based on the aggregation of predictions from all the models.
When bagging with decision trees, we are less concerned about individual trees overfitting the training data. For this reason and for efficiency, the individual decision trees are grown deep (e.g. few training samples at each leaf-node of the tree) and the trees are not pruned. These trees will have both high variance and low bias. These are important characterize of sub-models when combining predictions using bagging. The only parameters when bagging decision trees is the number of samples and hence the number of trees to include. This can be chosen by increasing the number of trees on run after run until the accuracy begins to stop showing improvement
Bagging
The idea behind bagging is combining the results of multiple models (for instance, all decision trees) to get a generalized result. Here’s a question: If you create all the models on the same set of data and combine it, will it be useful? There is a high chance that these models will give the same result since they are getting the same input. So how can we solve this problem? One of the techniques is bootstrapping.
Bootstrapping is a sampling technique in which we create subsets of observations from the original dataset, with replacement. The size of the subsets is the same as the size of the original set.
Bagging (or Bootstrap Aggregating) technique uses these subsets (bags) to get a fair idea of the distribution (complete set). The size of subsets created for bagging may be less than the original set.

Multiple subsets are created from the original dataset, selecting observations with replacement.
A base model (weak model) is created on each of these subsets.
The models run in parallel and are independent of each other.
The final predictions are determined by combining the predictions from all the models.

3.1.What is the intuition behind Bagging?
The idea behind bagging is combining the results of multiple models (for instance, all decision trees) to get a generalized result. Bagging (or Bootstrap Aggregating) technique uses subsets (bags) to get a fair idea of the distribution (complete set).
4.Boosting
Is a sequential process, where each subsequent model attempts to correct the errors of the previous model.
Boosting refers to a group of algorithms that utilize weighted averages to make weak learners into stronger learners. Unlike bagging that had each model run independently and then aggregate the outputs at the end without preference to any model. Boosting is all about “teamwork”. Each model that runs, dictates what features the next model will focus on.
Boosting
Before we go further, here’s another question for you: If a data point is incorrectly predicted by the first model, and then the next (probably all models), will combining the predictions provide better results? Such situations are taken care of by boosting.
Boosting is a sequential process, where each subsequent model attempts to correct the errors of the previous model. The succeeding models are dependent on the previous model. Let’s understand the way boosting works in the below steps.
A subset is created from the original dataset.
Initially, all data points are given equal weights.
A base model is created on this subset.
This model is used to make predictions on the whole dataset.

Errors are calculated using the actual values and predicted values.
The observations which are incorrectly predicted, are given higher weights. (Here, the three misclassified blue-plus points will be given higher weights)
Another model is created and predictions are made on the dataset. (This model tries to correct the errors from the previous model)
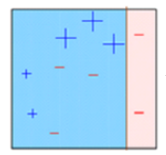
Similarly, multiple models are created, each correcting the errors of the previous model.
The final model (strong learner) is the weighted mean of all the models (weak learners).
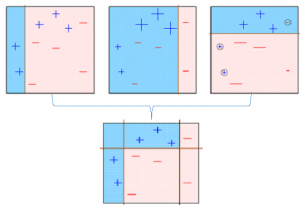
Thus, the boosting algorithm combines a number of weak learners to form a strong learner. The individual models would not perform well on the entire dataset, but they work well for some part of the dataset. Thus, each model actually boosts the performance of the ensemble.

5. Does ensemble learning improve my machine learning model?
In a word, yes! And that too drastically! Ensemble learn can improve the results of your machine learning even exponentially at times. There are two major benefits of Ensemble models:
More accurate predictions(closer to the actual value)
Combining multiple simple models to make a strong model improves the stability of the overall machine learning model.
What is the difference between Bagging and Boosting?
While both bagging and boosting involve creating subsets, bagging makes these subsets randomly, while boosting prioritizes misclassified subsets. Additionally, at the final step in bagging, the weighted average is used, while boosting uses majority weighted voting.
Advanced Ensemble Techniques
Stacking
Blending
Bagging
Boosting
Stacking
Stacking is an ensemble learning technique that uses predictions from multiple models (for example decision tree, knn or svm) to build a new model. This model is used for making predictions on the test set. Below is a step-wise explanation for a simple stacked ensemble:
The train set is split into 10 parts.
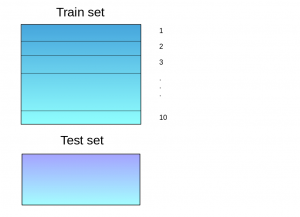
A base model (suppose a decision tree) is fitted on 9 parts and predictions are made for the 10th part. This is done for each part of the train set.

The base model (in this case, decision tree) is then fitted on the whole train dataset.
Using this model, predictions are made on the test set.

Steps 2 to 4 are repeated for another base model (say knn) resulting in another set of predictions for the train set and test set.

The predictions from the train set are used as features to build a new model.

This model is used to make final predictions on the test prediction set.
Sample code:
We first define a function to make predictions on n-folds of train and test dataset. This function returns the predictions for train and test for each model.
Now we’ll create two base models – decision tree and knn.
Create a third model, logistic regression, on the predictions of the decision tree and knn models.
In order to simplify the above explanation, the stacking model we have created has only two levels. The decision tree and knn models are built at level zero, while a logistic regression model is built at level one. Feel free to create multiple levels in a stacking model.
Blending
Blending follows the same approach as stacking but uses only a holdout (validation) set from the train set to make predictions. In other words, unlike stacking, the predictions are made on the holdout set only. The holdout set and the predictions are used to build a model which is run on the test set. Here is a detailed explanation of the blending process:
The train set is split into training and validation sets.

Model(s) are fitted on the training set.
The predictions are made on the validation set and the test set.
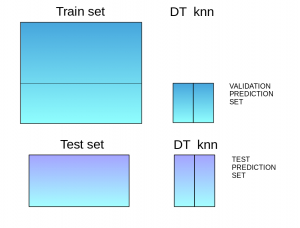
The validation set and its predictions are used as features to build a new model.
This model is used to make final predictions on the test and meta-features.
Sample Code:
We’ll build two models, decision tree and knn, on the train set in order to make predictions on the validation set.
Combining the meta-features and the validation set, a logistic regression model is built to make predictions on the test set.
Bagging algorithms:
Bagging meta-estimator
Random forest
Boosting algorithms:
AdaBoost
GBM
XGBM
Light GBM
CatBoost
Last updated