# Advanced Language Model Questions
**1.What are the differences between GPT and GPT-2? (From Lilian Weng)**
* [Layer normalization](https://arxiv.org/abs/1607.06450) was moved to the input of each sub-block, similar to a residual unit of type [“building block”](https://arxiv.org/abs/1603.05027) (differently from the original type [“bottleneck”](https://arxiv.org/abs/1512.03385), it has batch normalization applied before weight layers).
* An additional layer normalization was added after the final self-attention block.
* A modified initialization was constructed as a function of the model depth.
* The weights of residual layers were initially scaled by a factor of 1/√n where n is the number of residual layers.
* Use larger vocabulary size and context size.
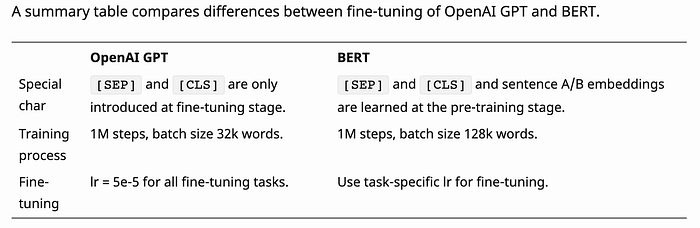
> **2. What are the differences between GPT and BERT?**
* GPT is not bidirectional and has no concept of masking
* BERT adds next sentence prediction task in training and so it also has a segment embedding
**3.What are the differences between BERT and ALBERT v2?**
* Embedding matrix factorisation(helps in reducing no. of parameters)
* No dropout
* Parameter sharing(helps in reducing no. of parameters and regularisation)
**4. How does parameter sharing in ALBERT affect the training and inference time?**
No effect. Parameter sharing just decreases the number of parameters.
**5. How would you reduce the inference time of a trained NN model?**
* Serve on GPU/TPU/FPGA
* 16 bit quantisation and served on GPU with fp16 support
* Pruning to reduce parameters
* Knowledge distillation (To a smaller transformer model or simple neural network)
* Hierarchical softmax/Adaptive softmax
* You can also cache results as explained here.
6\. **Slanted triangular learning rates**
The learning rates are not kept constant throughout the fine-tuning process. Initially, for some epochs, they are increased linearly with a steep slope of increase. Then, for multiple epochs, they are decreased linearly with a gradual slope. This was found out to give good performance of the model.
7\. **Concat Pooling**
\
In general, in text classification, the important words are only a few words and may be a small part of the entire document, especially if the documents are large. Thus, to avoid loss of information, the hidden state vector is concatenated with the max-pooled and mean-pooled form of the hidden state vector.
\
8\. **Gradual Unfreezing**
\
When all layers are fine-tuned at the same time, there is a risk of catastrophic forgetting. Thus, initially all layers except the last one are frozen and the fine-tuning is done for one epoch. One-by-one the layers are unfrozen and fine-tuning is done. This is repeated till convergence.
9