# Question on imp techniques
#### 1. What is meant by data augmentation? What are some of the ways in which data augmentation can be done in NLP projects?
NLP has some methods through which we can take a small dataset and use that in order to create more data. This is called data augmentation. In this, we use language properties to create text that is syntactically similar to the source text data.
Some of the ways in which data augmentation can be done in NLP projects are as follows:
* Replacing entities
* TF-IDF–based word replacement
* Adding noise to data
* Back translation
* Synonym replacement
* Bigram flipping
#### 2. What is the meaning of Text Normalization in NLP?
Consider a situation in which we’re operating with a set of social media posts to find information events. Social media textual content may be very exceptional from the language we’d see in, say, newspapers. A phrase may be spelt in multiple ways, such as in shortened forms, (for instance, with and without hyphens), names are usually in lowercase, and so on. When we're developing NLP tools to work with such kinds of data, it’s beneficial to attain a canonical representation of textual content that captures these kinds of variations into one representation. This is referred to as text normalization.
Converting all text to lowercase or uppercase, converting digits to text (e.g., 7 to seven), expanding abbreviations, and so on are some frequent text normalisation stages.
**3. What are the steps to follow when building a text classification system?**
When creating a text classification system, the following steps are usually followed:
* Gather or develop a labelled dataset that is appropriate for the purpose.
* Decide on an evaluation metric after splitting the dataset into two (training and test) or three parts: training, validation (i.e., development), and test sets (s).
* Convert unprocessed text into feature vectors.
* Utilize the feature vectors and labels from the training set to train a classifier.
* Benchmark the model's performance on the test set using the evaluation metric(s) from Step 2.
* Deploy the model and track its performance to serve a real-world use case.
\
**4. What do you mean by a Bag of Words (BOW)?**
The **Bag of Words** model is a popular one that uses word frequency or occurrences to train a classifier. This methodology generates a matrix of occurrences for documents or phrases, regardless of their grammatical structure or word order.
A bag-of-words is a text representation that describes the frequency with which words appear in a document. It entails two steps:
* A list of terms that are well-known.
* A metric for determining the existence of well-known terms.
Because any information about the sequence or structure of words in the document is deleted, it is referred to as a "bag" of words. The model simply cares about whether or not recognised terms appear in the document, not where they appear.
**5. What is Latent Semantic Indexing (LSI) in NLP?**
**Latent Semantic Indexing** (LSI), also known as Latent Semantic Analysis, is a mathematical method for improving the accuracy of information retrieval. It aids in the discovery of hidden(latent) relationships between words (semantics) by generating a set of various concepts associated with the terms of a phrase in order to increase information comprehension. Singular value decomposition is the NLP technique utilised for this aim. It's best for working with small groups of static documents.
\
**6.What do you mean by Autoencoders?**
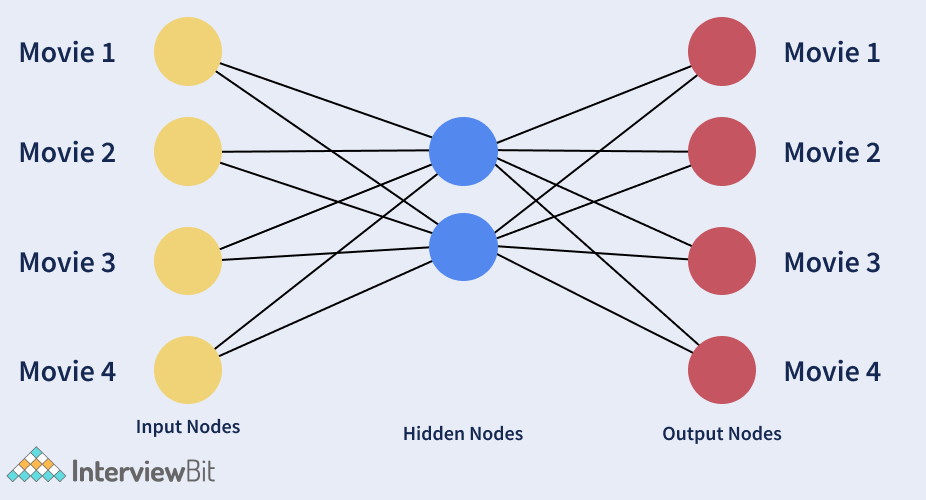
A network that is used for learning a vector representation of the input in a compressed form, is called an autoencoder. It is a type of unsupervised learning since labels aren’t needed for the process. This is mainly used to learn the mapping function from the input. In order to make the mapping useful, the input is reconstructed from the vector representation. After training is complete, the vector representation that we get helps encode the input text as a dense vector. Autoencoders are generally used to make feature representations.
In the figure below, the hidden layer depicts a compressed representation of the source data that captures its essence. The input representation is reconstructed by the output layer called the decoder.
**7. What do you mean by Masked language modelling?**
Masked language modelling is an NLP technique for extracting the output from a contaminated input. Learners can use this approach to master deep representations in downstream tasks. Using this NLP technique, you may predict a word based on the other words in the sentence.
The following is the process for Masked language modelling:
* Our text is tokenized. We start with text tokenization, just as we would with transformers.
* Make a tensor of labels. We're using a labels tensor to calculate loss against — and optimise towards — as we train our model.
* Tokens in input ids are masked. We can mask a random selection of tokens now that we've produced a duplicate of input ids for labels.
* Make a loss calculation. We use our model to process the input ids and labels tensors and determine the loss between them.
8\. What is the difference between learning latent features using SVD and getting embedding vectors using deep network?
SVD uses linear combination of inputs while a neural network uses non-linear combination.
**9. Number of parameters in an LSTM model with bias**
4(��*h+h²+h*) where 𝑚 is input vectors size and *h* is output vectors size a.k.a. hidden
The point to see here is that *mh* dictates the model size as m>>h. Hence it's important to have a small vocab.
**10. Time complexity of LSTM**
seq\_length\*hidden²
**11. Time complexity of transfomer**
seq\_length²\*hidden
When hidden size is more than the seq\_length(which is normally the case), transformer is faster than LSTM.
\
**12.Why self-attention is awesome?**
“In terms of computational complexity, self-attention layers are faster than recurrent layers when the sequence length n is smaller than the representation dimensionality d, which is most often the case with sentence representations used by state-of-the-art models in machine translations, such as word-piece and byte-pair representations.” — from Attention is all you need
**13. Should we do cross-validation in deep learning?**
No.
The variance of cross-folds decrease as the samples size grows. Since we do deep learning only if we have samples in thousands, there is not much point in cross validation.
**14. What is the difference between hard and soft parameter sharing in multi task learning?**
In hard sharing, we train for all the task at once and update weight based on all the losses. In soft, we train for only one task at a time.
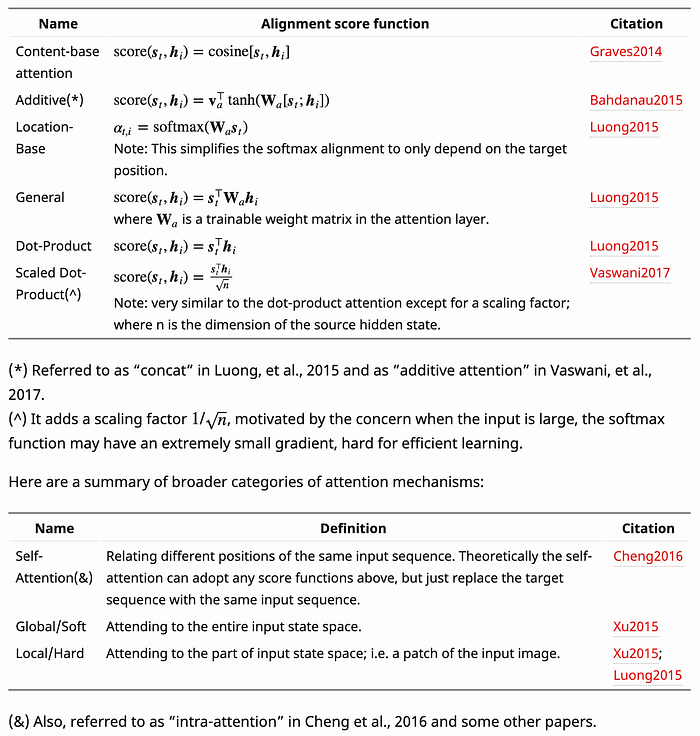
**15. What are the different types of attention mechanism?**
16\. Difference between BatchNorm and LayerNorm?
BatchNorm — Compute the mean and var at each layer for every minibatch
LayerNorm — Compute the mean and var for every single sample for each layer independently
\
**17. Why does the transformer block have LayerNorm instead of BatchNorm?**
Looking at the advantages of LayerNorm, it is robust to batch size and works better as it works at the sample level and not batch level.
As batch normalization is dependent on batch size, it's not effective for small batch sizes. Layer normalization is independent of the batch size, so it can be applied to batches with smaller sizes as well
**18. Which is the most used layer in transformer?**
Dropout
**19. What are the tricks used in ULMFiT? (Not a great questions but checks the awareness)**
* LM tuning with task text
* Weight dropout
* Discriminative learning rates for layers
* Gradual unfreezing of layers
* Slanted triangular learning rate schedule
This can be followed up with a question on explaining how they help.
**20. Tell me a language model which doesn’t use dropout**
ALBERT v2 — This throws a light on the fact that a lot of assumptions we take for granted are not necessarily true. The regularization effect of parameter sharing in ALBERT is so strong that dropouts are not needed. (ALBERT v1 had dropouts.)
21\.